v2206: New and improved parallel operation
TOP
Optional constraints can be applied to the decomposePar utility, using the constraints section of the decomposeParDict. The singleProcessorFaceSets constraint can be used to put all faces of a faceSet on the same processor. In v2206 the logic has been extended to work in parallel and e.g. redistributePar -parallel.
A typical use may be to keep cyclicAMI faces on a single processor, e.g. as needed for implicit running or particle tracking:
method ptscotch;
constraints
{
keepCyclicAtOnePatch
{
type singleProcessorFaceSets;
sets
(
(fanLeftFaceSet -1)
(fanRightFaceSet -1)
);
enabled true;
}
}
Tutorials
- any tutorial with singleProcessorFaceSets constraint
Source code
TOP
Parallel Communication
This version includes a major rework of some low-level MPI parallel communication components related to the Pstream library. The changes include updates as part of our regular code development, changes related to exaFOAM project activities and a very big thank you goes to the researchers Tetsuo AOYAGI, Yoshiaki INOUE and Akira AZAMI from RIST working on performance improvements on Fugaku.
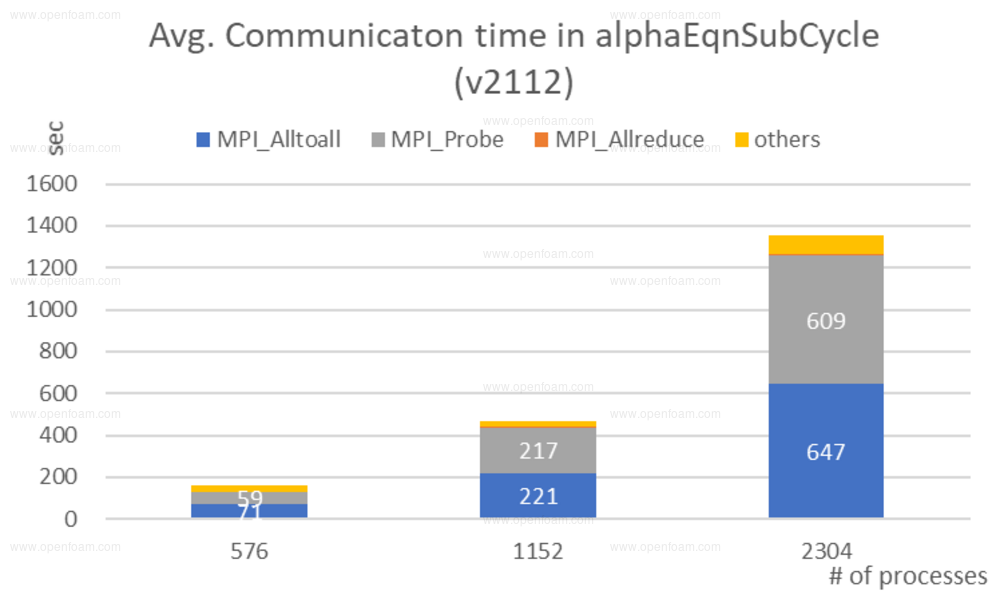
The RIST investigators noticed particularly poor performance of the interIsoFoam solver at larger processor counts, which they traced back to a degenerate communication pattern:
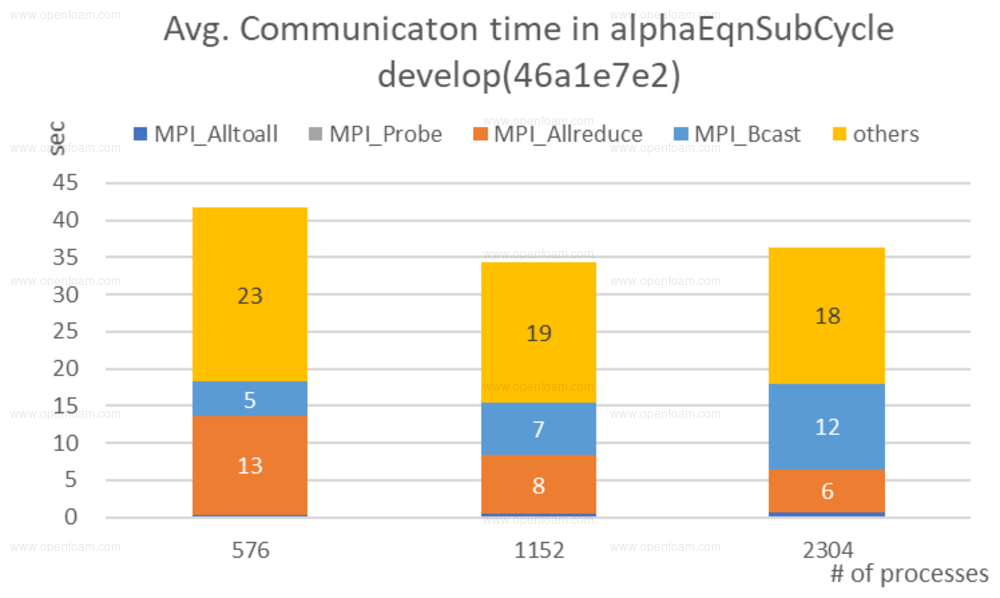
Their solution combined a limited communication stencil with MPI broadcasts to avoid many all-to-all and point-to-point communications:
The scale of improvements that they achieved for interIsoFoam is truly impressive: from about 1300s to less than 50s communication time!
Short Overview of Updates
The reworking of Pstream is fairly extensive, but here are few points of interest:
- new Pstream::broadcast and Pstream::broadcasts operations. Can replace multiple one-to-many communications with a single MPI_Bcast (based on the work from RIST).
- tree-based scattering largely replaced with broadcast to leverage network-optimized MPI intrinsics.
- additional Pstreams access methods, including rewind, peek etc. to improve memory reuse etc.
- additional PstreamBuffers communication modes, i.e. gather/scatter, neighbour/neighbour and specialised topologically patterns.
- native MPI min/max/sum reductions for float/double/(u)int32_t/(u)int64_t types.