
v2606: New and improved infrastructure
TOP
This is the first release to support GPU offloading. It uses the C++17/20 std::execution policy to automatically run loops in parallel across multiple execution units, which may be GPU devices or cores sharing memory.
Background
In modern computer architectures, performance is increasingly limited not by raw computation but by the speed at which data can be transferred from memory to compute units. This work builds on previous GPU porting efforts; for the latest effort, Keysight/OpenCFD teamed up with the UK Science and Technology Facility Council (STFC), Exeter University, and major hardware providers (AMD and Nvidia) to apply modern C++ constructs to the most performance-critical parts of the code. The main areas addressed are:
- using algorithms that are not order-dependent and do not cause race conditions, e.g. cell-based rather than face-based loops
- offloading loops wherever possible using C++17 execution policies
- allocating memory where it is needed, using a memory pool backed by Umpire
- keeping changes at the lowest level so that the user-facing API is unaffected (field algebra, linear solvers, boundary evaluation)
- avoiding allocation of intermediate fields, e.g. by interpolating on-the-fly rather than creating an intermediate interpolated field, using expression templating
Thanks to:
- STFC: Jony Castagna, Mayank Kumar
- Exeter University: Gavin Tabor, Liam Berrisford
- AMD: Leopold Grinsberg, Kumar Saurabh
- Nvidia: Filippo Spiga, Matthew Martineau, Stan Posey; supplying hardware
Results
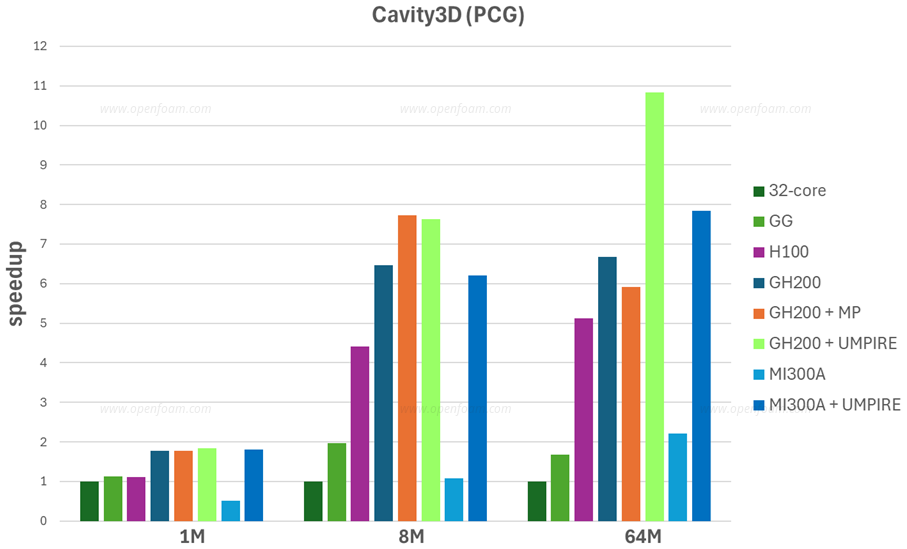
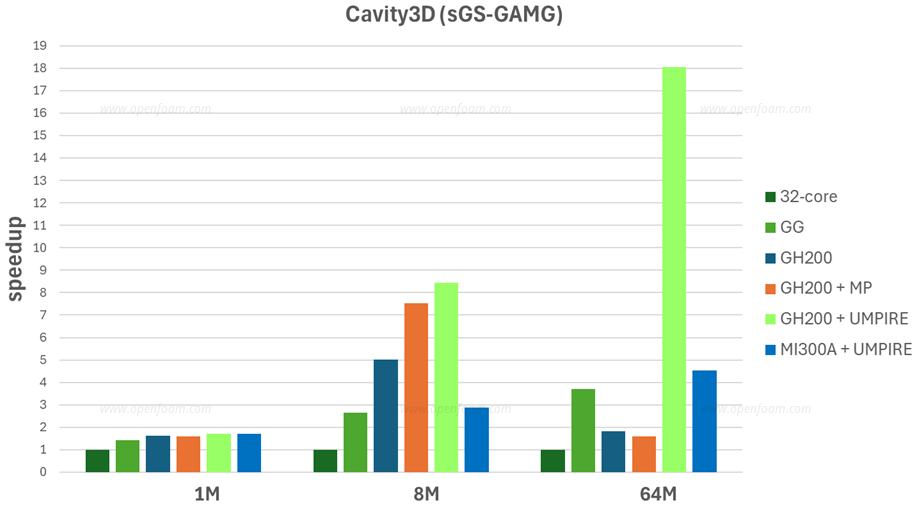
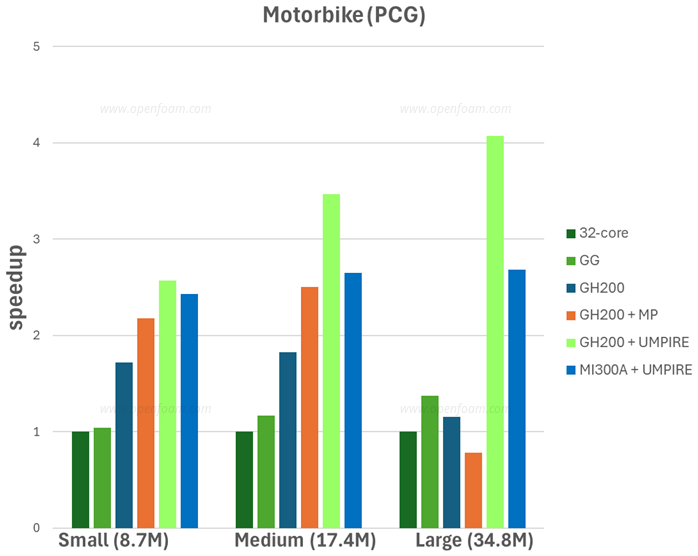
Even as a first implementation, the results are encouraging. The graph below shows the speed-up relative to a high-end 32-core CPU (Intel Xeon Gold 6448Y).
Memory management is critical. OpenFOAM uses UMPIRE to control where memory chunks reside and ensure efficient access for both CPU and GPU. This remains important even on architectures with unified memory such as GH100 or MI300A.
With a more complex linear solver configuration using GAMG and a specialised smoother, good speed-ups are achievable for larger cases. Please note that similar speed-ups should be possible on the MI300A and the performance is still evolving:
In the current state, there is no patch fusing, so every patch is handled separately. This causes noticeably worse performance for cases with large numbers of patches:
The current results are far from the theoretical maximum. Active work continues on patch merging (either built-in or as a pre-processing step), greater operation merging (kernels ideally perform complex operations with few intermediates), and avoiding intermediate fields.
Risks
- Do not use explicitly serial linear solver routines such as
DIC,DILU,GaussSeidel, orsymGaussSeidel. UseGAMGwithtwoStageGaussSeidelas a smoother instead. - The parallelisation used in the GPU version introduces non-deterministic behaviour: the ordering of operations can vary from run to run, and the loop structure may differ from the CPU version (e.g. over cells rather than faces). This affects the truncation error, so results will be slightly different compared to CPU runs.
- GPU parallelisation and offloading is a compile-time option, packaged as a new architecture so that the same source tree can be compiled for either CPU or GPU.
- The current GPU work is still on a separate development track and may be slightly behind the main development line. Care has been taken to ensure that the GPU version behaves identically to the CPU version unless compiled for GPU.
- Using CPU threading (
-stdpar=multicore) is not properly supported (work-in-progress)
Cases
- Selected cases from the HPC committee have been used for testing
Source code
- The code is made available as a branch on a development repository here: source code
- Please see the repo's wiki and associated guides to get started quickly
- After further testing and feedback from the Community we intend to integrate the code in the OpenFOAM v2612 release
TOP
As part of the ongoing modernisation of the codebase, more methods are now constexpr and noexcept, which assists the compiler when targeting offloading architectures.
Some of the basic OpenFOAM types (FixedList, Pair, Tuple2, edge, and others) now also support C++17 structured bindings, enabling more natural and expressive code. For example:
auto [minId, maxId] = findMinMax_locations(fld)Various list type detection traits (e.g. is_dynamiclist_v, is_fixedlist_v, is_indirectlist_v) have been added to assist with template code.
Some C++20 type traits (e.g. remove_cvref, type_identity) have been backported to simplify complex template code. The stdFoam::is_template_base_of_v provides a functional equivalent of std::is_base_of that handles templated classes. Other additions such as vectorspace_data() simplify component-wise handling in templated code.
TOP
Debugging on macOS has become easier with new internal handling of the error printStack function, which now uses the atos utility. This replaces the older addr2line replacement that stopped working correctly on more recent macOS versions.
For general programming and debugging, a new error::demangle() function is available that returns symbol names in human-readable form.
To help track down memory hotspots, two high-level methods are now available for collecting the memory high-water mark on a per-node basis.
The error::list_mem_hwm() method returns a list of the per-node summed memory high-water mark values:
Info<< "mem.hwm = " << flatOutput(error::list_mem_hwm()) << nl;The general macros PrintMemoryIn(functionName) and PrintMemoryInFunction can be used to report the current per-node memory high-water mark as a decorated string in the following form:
[node0][mem.hwm=<digits>](file.cxx:123)The memory high-water mark is also included in the output when profiling is active.
TOP
The compilation rules have been extended to support cross-compilation for Windows ARM64 targets using the llvm-mingw infrastructure.
The build_llvm-mingwARM64.Dockerfile provides an example setup. Note that MPI support for Windows ARM64 is currently quite limited.