
v2512: New and improved numerics
TOP
Building on existing gradient caching functionality, this release introduces in-place gradient updates that eliminate repeated memory allocations, reducing computational overhead for gradient-intensive simulations.
Gradient caching is configured in the system/fvSolution file. Users can enable caching for all gradients or specific variables using pattern matching, e.g.:
cache
{
"grad(.*)";
}
The enhanced caching system allocates gradient storage once and updates it in place when field values change, delivering measurable performance gains with minimal configuration effort.
A demonstration case is available in $FOAM_TUTORIALS/incompressible/simpleFoam/pitzDaily_fused. Performance testing on this tutorial shows progressive improvements:
| Gradient scheme | Time [s] |
|---|---|
| Gauss | 1.63 |
| fusedGauss | 1.56 |
| fusedGauss + cache all | 1.40 |
Users can monitor caching behavior by enabling debug output:
DebugSwitches
{
solution 1;
}
This typically shows messages:
Cache: Calculating and caching grad(U): allocating and calculating a gradient.Cache: Reusing grad(U): found a cached grad(U) originating from the same U.Cache: Updating grad(U): found cached grad(U) but U has changed so update.
Source code
Tutorials
Merge request
TOP
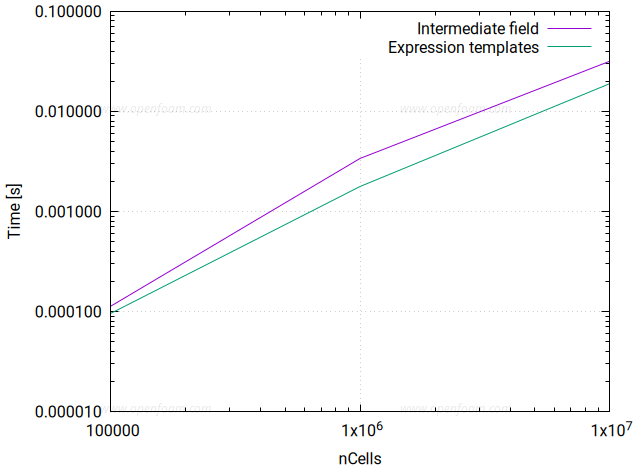
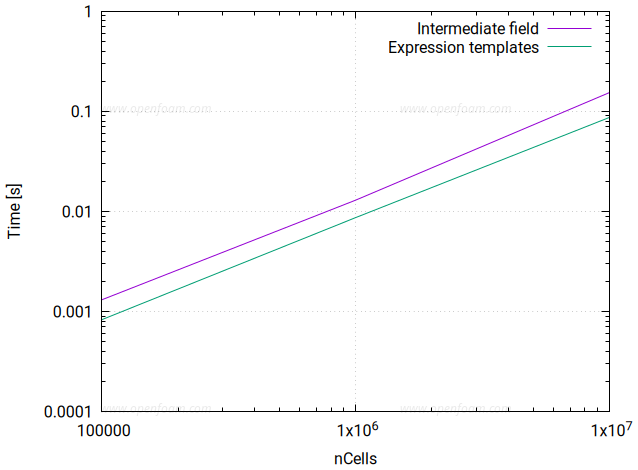
This release includes an initial version of an expression templates library that transforms how field operations are executed. This powerful optimization technique eliminates intermediate field allocations, fuses multiple operations into single computational kernels, and enables hardware acceleration including GPU offloading.
The basic functionality operates at the container level (List) and is extended to operate at the geometric field level (volScalarField, etc.). A practical example is the family of fused schemes.
Please note that the current functionality is not yet frozen and the code remains under active development. Below shows the testing of (volScalarField) expressions on a CPU:
Simple algebra: c = a + b
Complex algebra: c = cos(a + 0.5*sqrt(b-sin(a)))
Notes
Expression evaluation for geometric fields is divided into three separate evaluations: internal field, uncoupled patch fields, and coupled patch fields. An innovative contribution from AMD enables fused patch evaluation where all uncoupled (or coupled) patches are processed by a single kernel, dramatically improving performance for cases with many boundary patches.
Uses
- The current functionality has been tested for basic
Lists andGeometricFields. - Off-loading functionality has been tested on mainstream unified-memory architectures from AMD and NVIDIA.
- The current syntax is quite verbose; work is underway to simplify its use.
- Expression-templating can be applied to any
GeometricField, e.g. surface fields or finite-area fields. - Internally, versions of the incompressible kEpsilon and kOmega models have been created, demonstrating a straightforward conversion of existing models.
Source code
- $FOAM_SRC/OpenFOAM/expressionTemplates/ListExpression.H
- $FOAM_SRC/OpenFOAM/expressionTemplates/GeometricFieldExpression.H
- $FOAM_SRC/fused/finiteVolume/fusedGaussLaplacianSchemes.C
Tutorials
Merge request
TOP
Arbitrary Mesh Interpolation (AMI) stencils and weights can now be cached, offering the potential to significantly improve the performance of moving mesh simulations, particularly at high core counts.
The new caching eliminates parallel communications and stencil assembly during AMI construction by reusing stored information. Early testing demonstrated 10-30% speedup at high core counts for external aerodynamics cases with moving wheels.
Optimum performance was recovered when using a fixed time step, and a full rotation is divided into an integer number of steps. Here, cached information can be replayed directly. Otherwise a linear interpolation is applied between cached instances.
Cached values are stored in angular bins, specified using the [optional] cacheSize entry when defining the patch in the polyMesh/boundary file, e.g., to create bins using a 1 deg interval:
AMI1
{
type cyclicAMI;
AMIMethod faceAreaWeightAMI;
neighbourPatch AMI2;
...
// New optional entries
// Cache size: deactivated if not present/zero-sized
cacheSize 360;
// Always store a set of AMI data if the bin is empty
forceCache false;
// Maximum number of bins from current bin to search to construct
// the interpolation stencil. Default = 2
nThetaStencilMax 2;
}
Source code
- $FOAM_SRC/meshTools/AMIInterpolation/AMIInterpolation
- $FOAM_SRC/meshTools/AMIInterpolation/AMIInterpolation/AMICache.H
Tutorial
Merge request
TOP
The new decomposition agglomeration method for GAMG solvers leverages existing decomposition algorithms to provide researchers and advanced users with additional flexibility to explore multigrid coarsening strategies.
An example input:
p
{
solver GAMG;
smoother GaussSeidel;
agglomerator decomposition;
decompositionCoeffs
{
numberOfSubdomains 8;
method scotch;
}
// Optional renumbering
// renumber true;
// Optional avoid enforcing connectedness of each coarse level
// forceConnected false;
interpolateCorrection true;
nCellsInCoarsestLevel 8;
...
}
By controlling the numberOfSubdomains parameter, users can precisely tune coarsening levels to match their specific problem characteristics and computational requirements.
It is generally advisable to use second-order correction when using more than 2 coarsening levels. (interpolateCorrection true)
Note that the decomposition method is invoked at startup for each coarse cell, thereby adding to the overall cost. The connectivity enforcement step may generate additional coarse-level cells to maintain domain connectivity; however, this can be turned off by setting forceConnected to false. Users should note that decomposition methods, such as Scotch, may exhibit non-deterministic behavior depending on compilation options, potentially producing variation between consecutive runs.
Source code
Merge request
TOP
This improvement relates to the reproducibility of simulations that employ the geometric agglomeration (faceAreaPairGAMGAgglomeration). On certain architectures the agglomeration can vary from run to run. This arises when using Open-MP style offloading whereby agglomeration construction can take a different path. Any change in the initial agglomeration affects the complete agglomeration down to the coarsest level. This in turn leads to different convergence behaviour, partly mitigated by tightening tolerances.
Thanks to AMD for discovering and fixing the issue.
Source code
Gitlab issue
Attribution
- Advanced Micro Devices (AMD)